for Video Generation over Events
Events are not points.
Let them live in time.
Existing video generators know when a frame is, but not when an event lives. They encode time as discrete points, while events occupy intervals. This creates a structural mismatch: overlapping events collapse into ambiguous token sequences. TIE fixes it by generalizing RoPE from point-wise timestamps to interval-aware event keys.
Noise means errors in annotated event start and end times. TIE confines their effect to the interval margin.
nDTW over clean Finetuned under significant event-boundary noise.
EMD below clean Finetuned under significant event-boundary noise.
Latest updates on TIE.
A structural problem, not a scaling problem.
In 68% of general clips and over 99% of robotics & gameplay clips, multiple events overlap in time. Yet every modern multi-event generator rests on a single-active-prompt assumption.
Standard rotary embeddings assign each token a single timestamp. Events that span an interval — let alone overlap — collapse into ambiguous token sequences. Because all temporal evidence is concentrated at points or endpoints, timestamp noise directly perturbs the encoded phase. This is exactly the failure mode that appears in large-scale training, where event boundaries are produced by imperfect automatic annotators.
A textual event token carries an interval $I = [t^s, t^e]$. Cross-attention aggregates positional evidence over the entire span — so concurrent and overlapping events become first-class citizens.
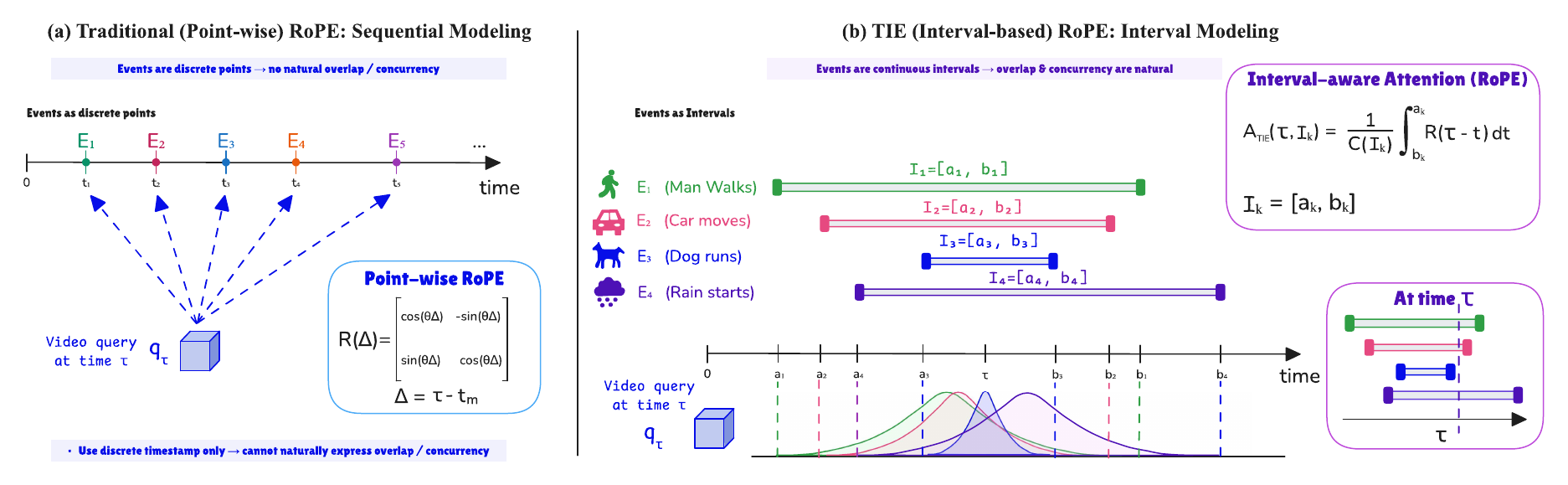
Point-wise RoPE cannot naturally model the point-to-interval activation pattern of an event. TIE supports it natively via interval integration.
No heuristics. The form of TIE is uniquely determined.
TIE asks a simple question: if a text token describes an event lasting from start to end, should attention see only one timestamp, two boundaries, or the whole interval?
For a video query $q_i$ at time $m_i$ and an event key $k_j$ with interval $I_j=[t_j^s,t_j^e]$, TIE defines the attention logit by aggregating RoPE evidence over the full temporal support of the event.
The cross-attention logit must integrate point-wise RoPE evidence across the event's full support. The interior of the interval is preserved, not collapsed to a center or boundary timestamp.
The final logit must reflect semantic relevance, not interval length. Normalization prevents long events from winning simply because they accumulate more temporal evidence.
The figure illustrates the modeling consequence of the two definitions above: point-wise RoPE samples a single timestamp, while TIE turns each event token into an interval-aware key whose evidence is integrated across time.
The center $c$ controls the rotation phase; the radius $r$ acts as a built-in temporal low-pass filter via $\operatorname{sinc}(\theta r)$. As $r \to 0$, RoTE reduces to standard RoPE — so it slots into any DiT with zero overhead.
Boundary perturbations only affect the marginal portion of the integration domain. The main theorem gives $\Delta_{\mathrm{RoTE}}=\mathcal{O}(\delta/r)$ when $\delta\le r/2$, while point-wise RoPE and boundary-only DoTE have local worst-case sensitivity $\mathcal{O}(\theta_{\max}\delta)$ with no decay in interval radius. This strict structural advantage is what makes interval-conditioned large-scale pretraining with VLM-derived annotations practical.
Visual quality preserved · Temporal control dramatically improved · Robust to annotation noise.
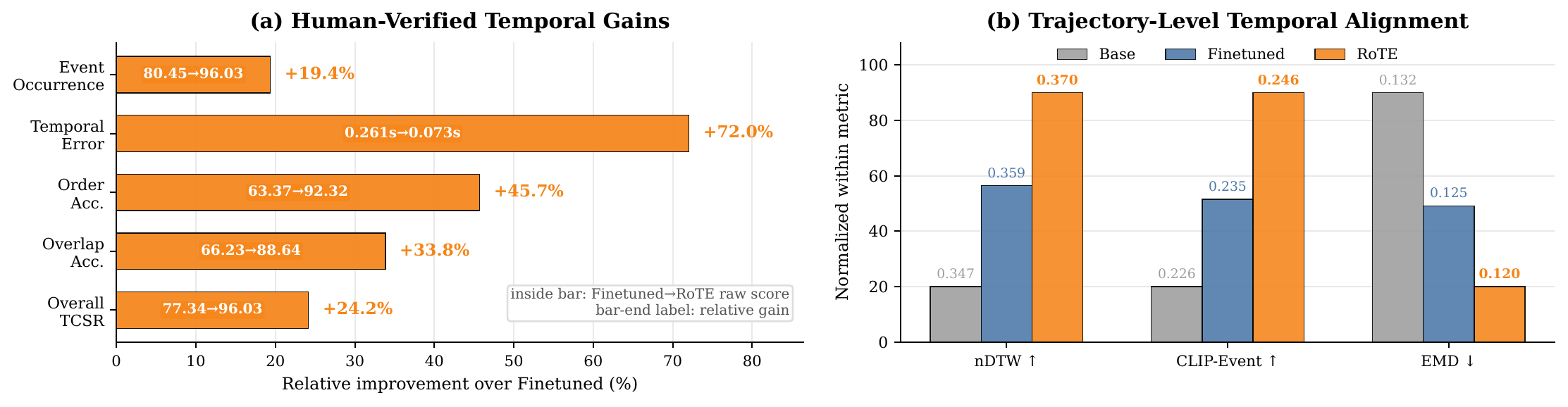
| Metric | Base | Finetuned | TIE (RoTE) | Δ vs. Finetuned |
|---|---|---|---|---|
| Temporal Constraint Satisfaction (TCSR) | — | 77.34% | 96.03% | +18.70 pp |
| Boundary Error | — | 0.261 s | 0.073 s | −0.188 s |
| Event Occurrence | — | 80.45% | 96.03% | +15.58 pp |
| Order Accuracy | — | 63.37% | 92.32% | +28.95 pp |
| Overlap Accuracy | — | 66.23% | 88.64% | +22.40 pp |
These numbers follow our human evaluation protocol: 100 structured prompts, one Finetuned and one TIE video per prompt, and 10 human annotators. For each event $e_i=[s_i,t_i]$, annotators verify occurrence $o_i$ and boundary deviations $b_i^s=\hat{s}_i-s_i,\; b_i^t=\hat{t}_i-t_i$.
Does the requested event appear?
Boundary deviation, with missing events penalized by target duration.
Checks before-after relations and whether concurrent events remain concurrent.
Prompt-level fraction of satisfied event, order, and overlap constraints.
Normalized dynamic time warping over a temporal cost matrix; higher means less temporal drift.
Frame-level video-text alignment between event descriptions and the generated event windows.
Earth Mover's Distance on the temporal event distribution; lower means the generated timeline is closer.
| Method | FID | FVD | Visual Quality | Temporal Cons. | Text Align. | CLIP-Event |
|---|---|---|---|---|---|---|
| Base | 59.68 | 357.51 | 2.73 | 2.78 | 2.68 | 0.226 |
| Finetuned | 43.74 | 234.40 | 3.03 | 3.01 | 2.86 | 0.235 |
| DoTE (boundary-only) | 43.84 | 234.79 | 3.05 | 3.01 | 2.88 | 0.241 |
| TIE (RoTE) | 42.53 | 217.29 | 3.10 | 3.05 | 2.92 | 0.246 |
Ablation isolates the gain: NoRoPE → DoTE shows boundary encoding helps; DoTE → RoTE shows interval interior matters; RoTE wins on every metric.
A core requirement for large-scale event-conditioned pretraining, not a minor stress test.
At scale, event intervals come from VLMs, action detectors, captioning systems, or other automatic annotators. Their boundaries are approximate, so the model must be robust to endpoint noise by design.
In contrast, point-wise RoPE and boundary-only DoTE concentrate temporal information on one timestamp or two
endpoints, yielding O(theta_max delta) sensitivity with no decay as the event interval grows.
RoTE(k,c,r) = C_r^-1 E_tau~U(I)[RoPE(k,tau)]
theta |sinc(theta r)| = |sin(theta r)| / r <= 1/r
Delta = O(theta_max delta)
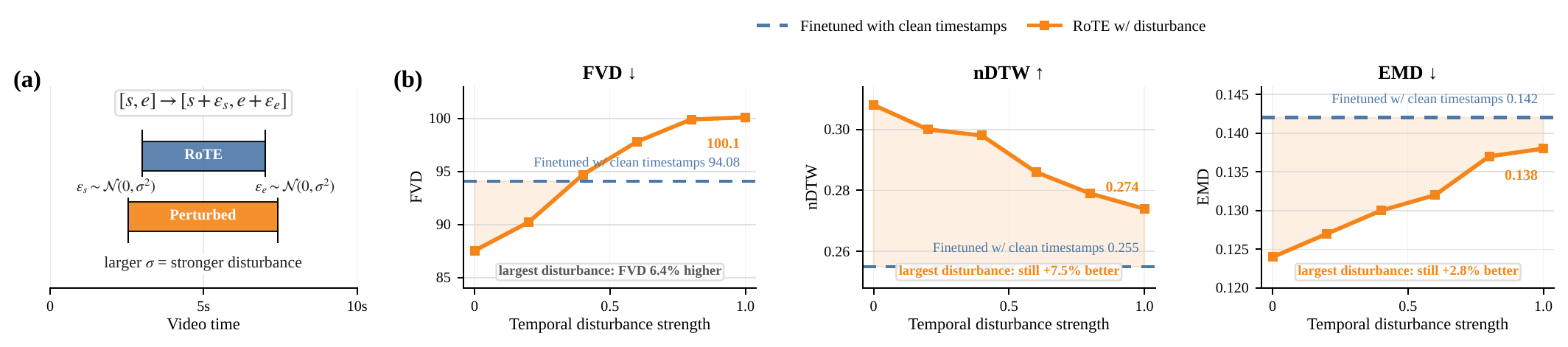
Following the paper, we perturb each interval as [s, e] -> [s + epsilon_s, e + epsilon_e] with Gaussian noise. A noise level of sigma = 0.6 is already large relative to many event durations; under this setting, RoTE still improves nDTW from 0.255 to 0.286 and reduces EMD from 0.142 to 0.132.
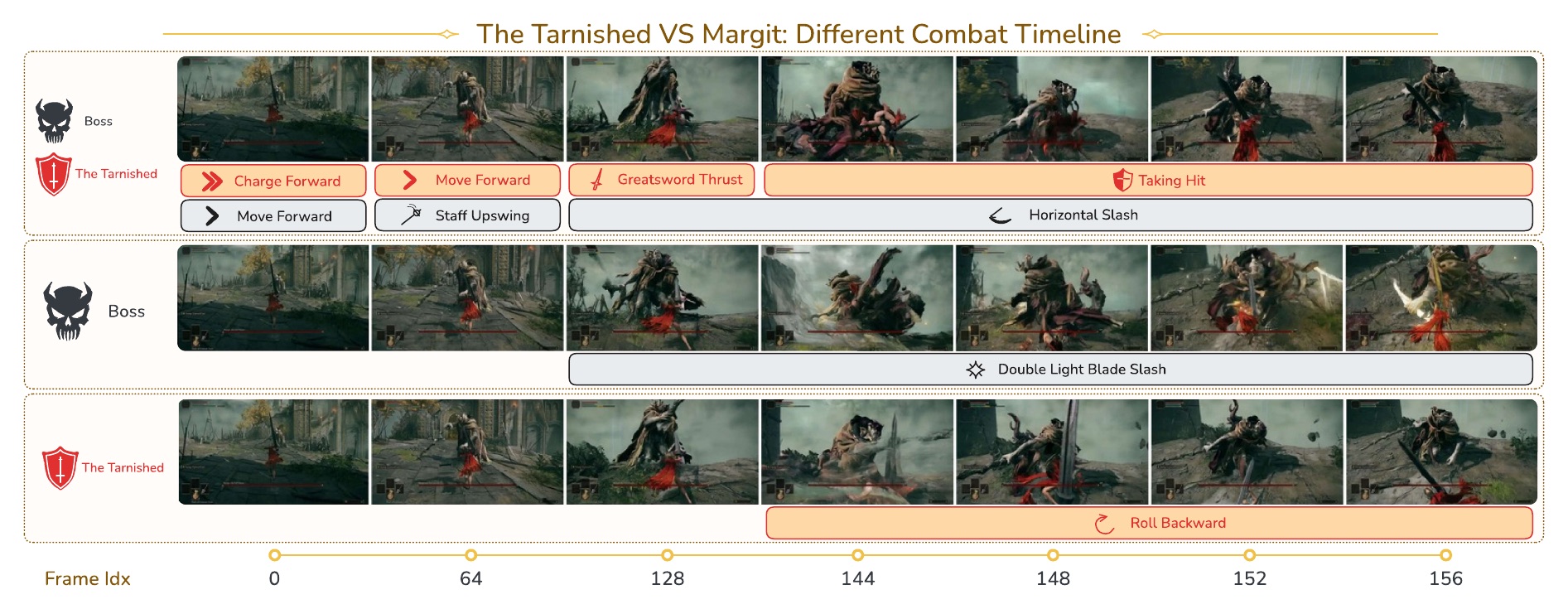
Concurrent events, multi-subject interactions. We compare TIE with existing prompt-based time control SoTA (Seedance 2.0), to see their time response performance under complex scenarios. We show videos with their accurate text prompts and timestamps in the below. We pick a few key visual changes for reader to better understand the differences. Traditional prompt-based methods struggle with temporal accuracy while TIE maintains robust performance.

A structured event-prompt dataset built specifically for the concurrent-event regime.
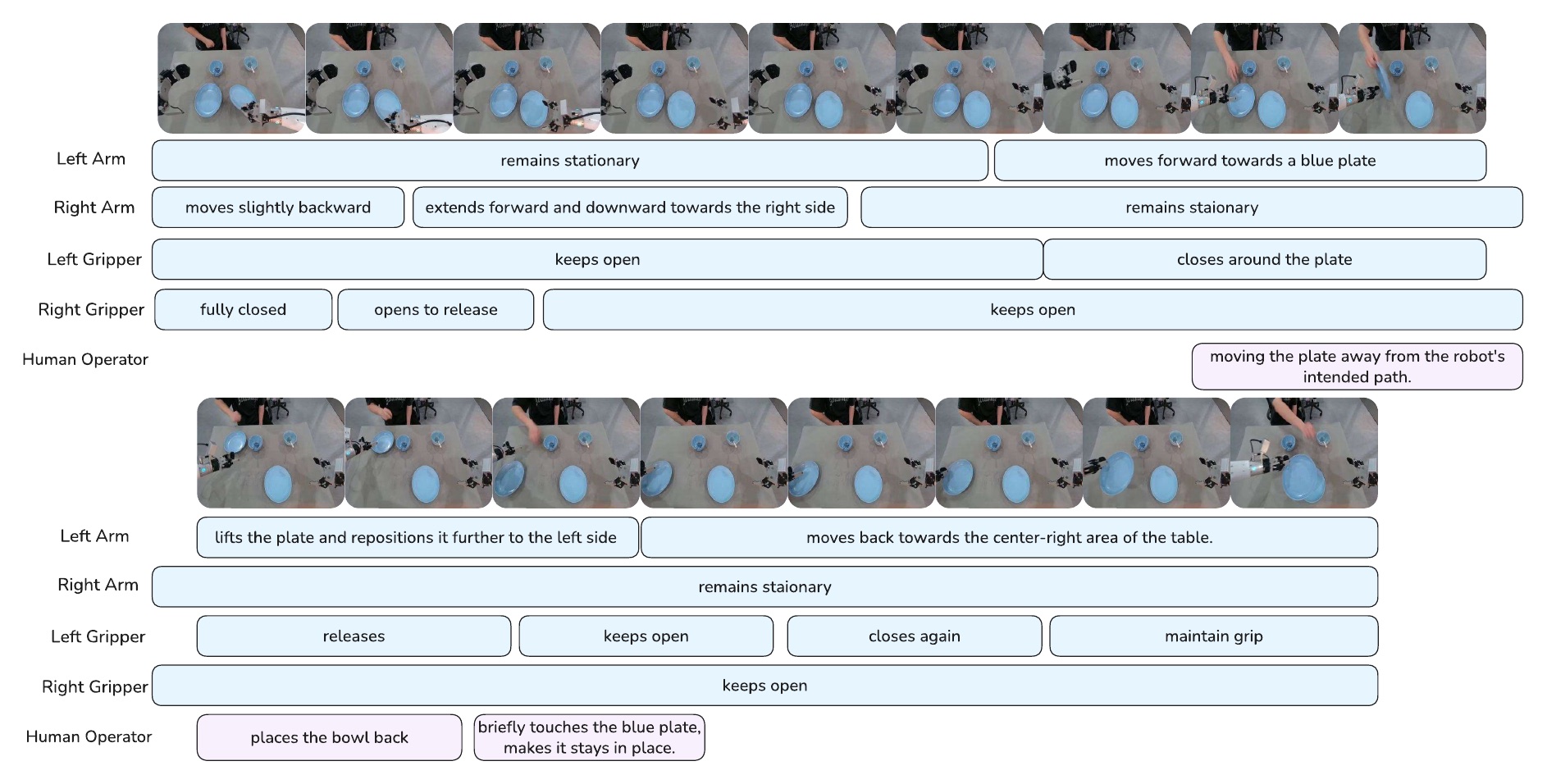
OmniEvents combines general videos, robotics demonstrations, and gameplay traces. Open-domain and robotics clips are annotated with a self-reflective VLM pipeline: structured JSON generation, deterministic temporal checks, semantic self-verification, and iterative refinement.
{
"subject": "left arm",
"event": "closes around the spoon",
"start": 3.00,
"end": 9.00
}

General-domain web videos with structured event-interval annotations. 68% per-clip event overlap probability.
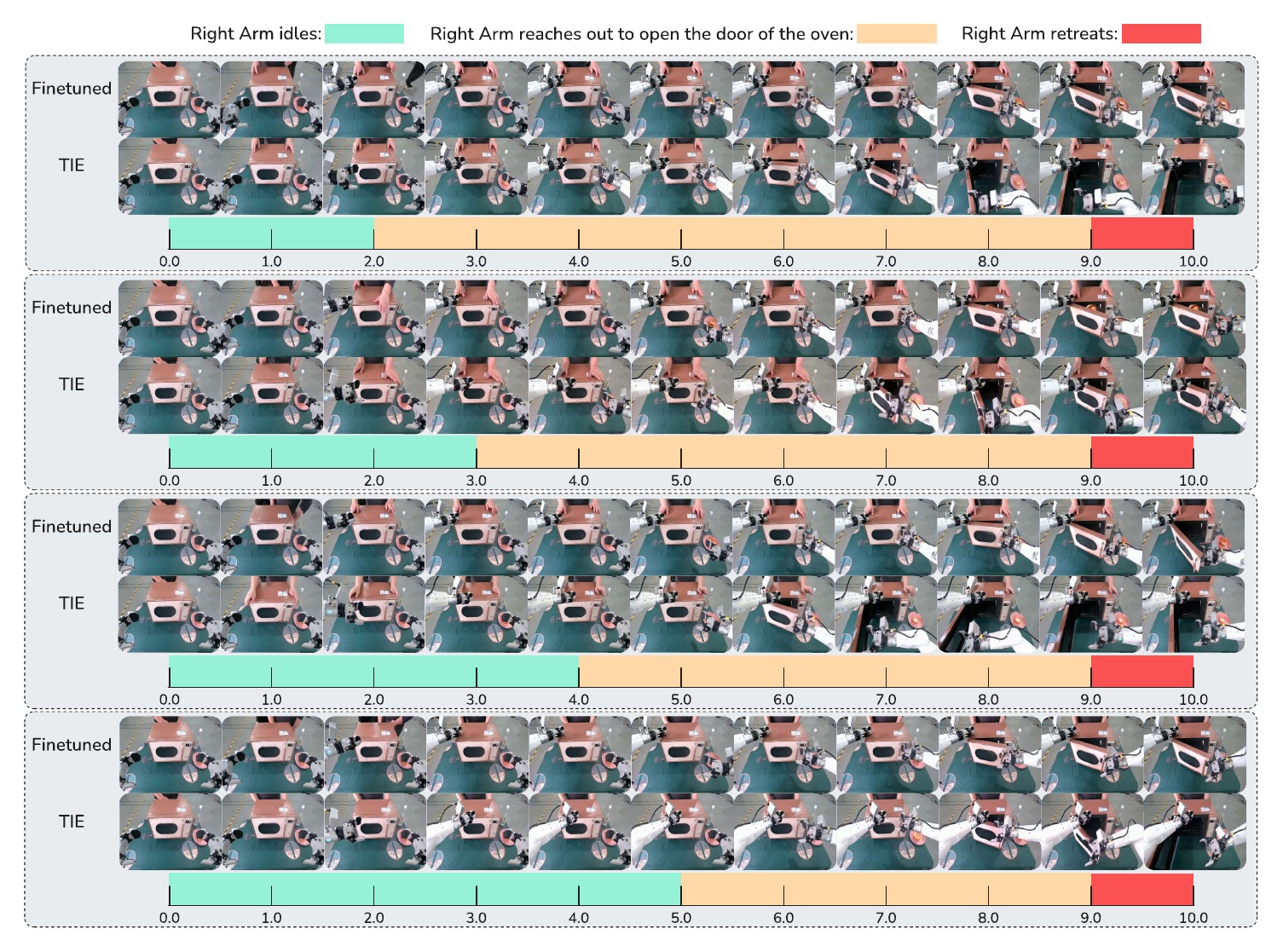
Task-specific robotics demonstrations from AgiBot, with event-level temporal supervision for bimanual manipulation.
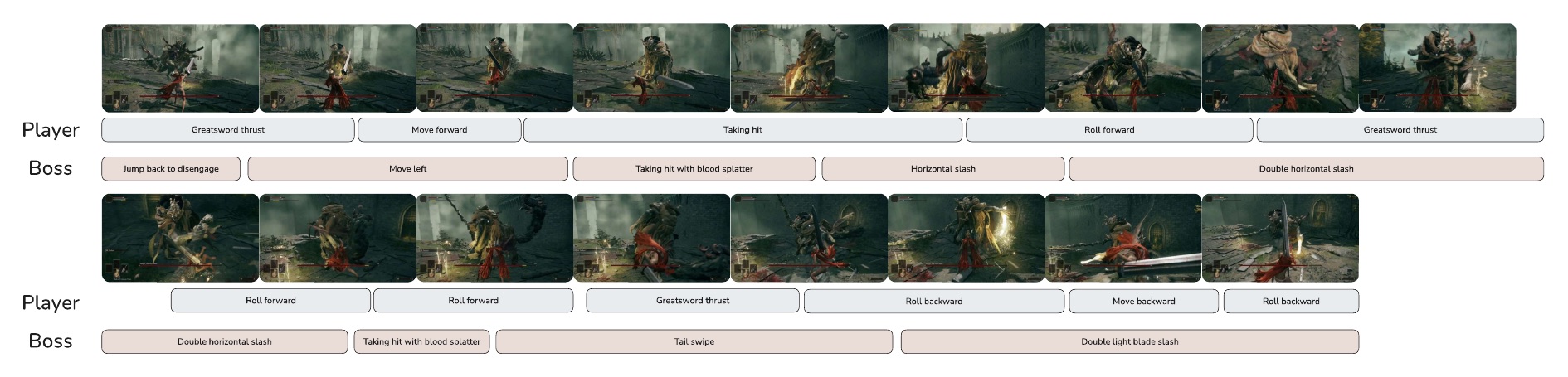
Elden Ring gameplay traces with frame-accurate event boundaries from game-state instrumentation.
| Dataset | Clips | Average events per clip | Average event duration (seconds) | Total events | Total event duration (seconds) | Total text-prompt length | Overlap probability |
|---|---|---|---|---|---|---|---|
| PexelsEvents | 253,903 | 4.72 | 3.67 | 1,197,973 | 4,391,589 | 164,639,876 | 68.00% |
| RoboticsEvents | 85,956 | 14.47 | 2.79 | 1,244,058 | 3,472,766 | 86,717,027 | 99.99% |
| GameEvents | 79,959 | 16.01 | 1.24 | 1,280,208 | 1,584,762 | 42,368,009 | 99.63% |
Dataset release coming soon
1University of Science and Technology of China · 2Matrix Team · 3Shanghai Jiao Tong University · 4Nanyang Technological University · 5University of Waterloo · 6The Pennsylvania State University · 7Zhongguancun Academy · 8The University of Hong Kong · 9NVIDIA Research
∗ Equal contribution. † Corresponding author. Project lead: Ruili Feng.








If you find this work helpful, please consider citing:
@misc{shu2026tie,
title = {TIE: Time Interval Encoding for Video Generation over Events},
author = {Shu, Zhilei and Zhu, Shangwen and Liang, Zihang and Li, Xiaofan
and Peng, Qianyu and Cui, Xinyu and Ye, Bo and Li, Yiming
and Cheng, Fan and Zhao, Jian and Cao, Yang
and Zha, Zheng-Jun and Feng, Ruili},
year = {2026},
eprint = {2605.10543},
archivePrefix = {arXiv},
primaryClass = {cs.CV},
doi = {10.48550/arXiv.2605.10543},
url = {https://arxiv.org/abs/2605.10543}
}